To make it more clear that it is the sum of all the nr_samples fields in the
addr[] entries, i.e.:
sym_hist->nr_samples = sum(sym_hist->addr[0 .. symbol__size(sym)]->nr_samples)
Committer notes:
Taeung had renamed it to total_samples, but using nr_samples, as in the
added explanation above, looks clearer and establishes the direct
connection, making clear it is about the _number_ of samples.
Signed-off-by: Taeung Song <treeze.taeung@gmail.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Namhyung Kim <namhyung@kernel.org>
Link: http://lkml.kernel.org/r/1500500211-16599-1-git-send-email-treeze.taeung@gmail.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
struct sym_hist has addr[] but it should have not only number of samples
but also the sample period. So use new struct symhist_entry to pave the
way to have that.
Committer notes:
This initial patch will only introduce the struct sym_hist_entry and use
only the nr_samples member, which makes the code clearer and paves the
way to save the period as well.
Signed-off-by: Taeung Song <treeze.taeung@gmail.com>
Suggested-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Namhyung Kim <namhyung@kernel.org>
Link: http://lkml.kernel.org/r/1500500205-16553-1-git-send-email-treeze.taeung@gmail.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
For marking fused instructions clearly this patch adds a line before the
first instruction of pair and joins it with the arrow of the jump to its
target.
For example, when "je" is selected in annotate view, the line before
cmpl is displayed and joins the arrow of "je".
│ ┌──cmpl $0x0,argp_program_version_hook
81.93 │ ├──je 20
│ │ lock cmpxchg %esi,0x38a9a4(%rip)
│ │↓ jne 29
│ │↓ jmp 43
11.47 │20:└─→cmpxch %esi,0x38a999(%rip)
That means the cmpl+je is a fused instruction pair and they should be
considered together.
Changelog:
v3: Use Arnaldo's fix to improve the arrow origin rendering. To get the
evsel->evlist->env->cpuid, save the evsel in annotate_browser.
v2: new function "ins__is_fused" to check if the instructions are fused.
Signed-off-by: Yao Jin <yao.jin@linux.intel.com>
Tested-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Andi Kleen <ak@linux.intel.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Kan Liang <kan.liang@intel.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Link: http://lkml.kernel.org/r/1499403995-19857-3-git-send-email-yao.jin@linux.intel.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Macro fusion merges two instructions to a single micro-op. Intel core
platform performs this hardware optimization under limited
circumstances.
For example, CMP + JCC can be "fused" and executed /retired together.
While with sampling this can result in the sample sometimes being on the
JCC and sometimes on the CMP. So for the fused instruction pair, they
could be considered together.
On Nehalem, fused instruction pairs:
cmp/test + jcc.
On other new CPU:
cmp/test/add/sub/and/inc/dec + jcc.
This patch adds an x86-specific function which checks if 2 instructions
are in a "fused" pair. For non-x86 arch, the function is just NULL.
Changelog:
v4: Move the CPU model checking to symbol__disassemble and save the CPU
family/model in arch structure.
It avoids checking every time when jump arrow printed.
v3: Add checking for Nehalem (CMP, TEST). For other newer Intel CPUs
just check it by default (CMP, TEST, ADD, SUB, AND, INC, DEC).
v2: Remove the original weak function. Arnaldo points out that doing it
as a weak function that will be overridden by the host arch doesn't
work. So now it's implemented as an arch-specific function.
Committer fix:
Do not access evsel->evlist->env->cpuid, ->env can be null, introduce
perf_evsel__env_cpuid(), just like perf_evsel__env_arch(), also used in
this function call.
The original patch was segfaulting 'perf top' + annotation.
But this essentially disables this fused instructions augmentation in
'perf top', the right thing is to get the cpuid from the running kernel,
left for a later patch tho.
Signed-off-by: Yao Jin <yao.jin@linux.intel.com>
Tested-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Andi Kleen <ak@linux.intel.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Kan Liang <kan.liang@intel.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Link: http://lkml.kernel.org/r/1499403995-19857-2-git-send-email-yao.jin@linux.intel.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
The option 'show-total-period' works fine without a option '-l'. But if
running 'perf annotate --stdio -l --show-total-period', you can see a
problem showing only zero '0' for number of samples.
Before:
$ perf annotate --stdio -l --show-total-period
...
0 : 400816: push %rbp
0 : 400817: mov %rsp,%rbp
0 : 40081a: mov %edi,-0x24(%rbp)
0 : 40081d: mov %rsi,-0x30(%rbp)
0 : 400821: mov -0x24(%rbp),%eax
0 : 400824: mov -0x30(%rbp),%rdx
0 : 400828: mov (%rdx),%esi
0 : 40082a: mov $0x0,%edx
...
The reason is it was missed to set number of samples of
source_line_samples, so set it ordinarily.
After:
$ perf annotate --stdio -l --show-total-period
...
3 : 400816: push %rbp
4 : 400817: mov %rsp,%rbp
0 : 40081a: mov %edi,-0x24(%rbp)
0 : 40081d: mov %rsi,-0x30(%rbp)
1 : 400821: mov -0x24(%rbp),%eax
2 : 400824: mov -0x30(%rbp),%rdx
0 : 400828: mov (%rdx),%esi
1 : 40082a: mov $0x0,%edx
...
Signed-off-by: Taeung Song <treeze.taeung@gmail.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Martin Liska <mliska@suse.cz>
Cc: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Wang Nan <wangnan0@huawei.com>
Fixes: 0c4a5bcea4 ("perf annotate: Display total number of samples with --show-total-period")
Link: http://lkml.kernel.org/r/1490703125-13643-1-git-send-email-treeze.taeung@gmail.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
It is wrong way to read link name from a build-id file. Because a
build-id file is not anymore a symbolic link but build-id directory of
it is symbolic link, so fix it.
For example, if build-id file name gotten from
dso__build_id_filename() is as below,
/root/.debug/.build-id/4f/75c7d197c951659d1c1b8b5fd49bcdf8f3f8b1/elf
To correctly read link name of build-id, use the build-id dir path that
is a symbolic link, instead of the above build-id file name like below.
/root/.debug/.build-id/4f/75c7d197c951659d1c1b8b5fd49bcdf8f3f8b1
Signed-off-by: Taeung Song <treeze.taeung@gmail.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Wang Nan <wangnan0@huawei.com>
Link: http://lkml.kernel.org/r/1490598638-13947-2-git-send-email-treeze.taeung@gmail.com
Fixes: 01412261d9 ("perf buildid-cache: Use path/to/bin/buildid/elf instead of path/to/bin/buildid")
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Often it is interesting to know how costly a given source line is in
total. Previously, one had to build these sums manually based on all
addresses that pointed to the same source line. This patch introduces
srcline as a sort key, which will do the aggregation for us.
Paired with the recent addition of showing inline frames, this makes
perf report much more useful for many C++ work loads.
The following shows the new feature in action. First, let's show the
status quo output when we sort by address. The result contains many hist
entries that generate the same output:
~~~~~~~~~~~~~~~~
$ perf report --stdio --inline -g address
# Children Self Command Shared Object Symbol
# ........ ........ ............ ................... .........................................
#
99.89% 35.34% cpp-inlining cpp-inlining [.] main
|
|--64.55%--main complex:655
| /home/milian/projects/kdab/rnd/hotspot/tests/test-clients/cpp-inlining/main.cpp:39 (inline)
| /usr/include/c++/6.3.1/complex:664 (inline)
| |
| |--60.31%--hypot +20
| | |
| | |--8.52%--__hypot_finite +273
| | |
| | |--7.32%--__hypot_finite +411
...
--35.34%--_start +4194346
__libc_start_main +241
|
|--6.65%--main random.tcc:3326
| /home/milian/projects/kdab/rnd/hotspot/tests/test-clients/cpp-inlining/main.cpp:39 (inline)
| /usr/include/c++/6.3.1/bits/random.h:1809 (inline)
| /usr/include/c++/6.3.1/bits/random.h:1818 (inline)
| /usr/include/c++/6.3.1/bits/random.h:185 (inline)
|
|--2.70%--main random.tcc:3326
| /home/milian/projects/kdab/rnd/hotspot/tests/test-clients/cpp-inlining/main.cpp:39 (inline)
| /usr/include/c++/6.3.1/bits/random.h:1809 (inline)
| /usr/include/c++/6.3.1/bits/random.h:1818 (inline)
| /usr/include/c++/6.3.1/bits/random.h:185 (inline)
|
|--1.69%--main random.tcc:3326
| /home/milian/projects/kdab/rnd/hotspot/tests/test-clients/cpp-inlining/main.cpp:39 (inline)
| /usr/include/c++/6.3.1/bits/random.h:1809 (inline)
| /usr/include/c++/6.3.1/bits/random.h:1818 (inline)
| /usr/include/c++/6.3.1/bits/random.h:185 (inline)
...
~~~~~~~~~~~~~~~~
With this patch and `-g srcline` we instead get the following output:
~~~~~~~~~~~~~~~~
$ perf report --stdio --inline -g srcline
# Children Self Command Shared Object Symbol
# ........ ........ ............ ................... .........................................
#
99.89% 35.34% cpp-inlining cpp-inlining [.] main
|
|--64.55%--main complex:655
| /home/milian/projects/kdab/rnd/hotspot/tests/test-clients/cpp-inlining/main.cpp:39 (inline)
| /usr/include/c++/6.3.1/complex:664 (inline)
| |
| |--64.02%--hypot
| | |
| | --59.81%--__hypot_finite
| |
| --0.53%--cabs
|
--35.34%--_start
__libc_start_main
|
|--12.48%--main random.tcc:3326
| /home/milian/projects/kdab/rnd/hotspot/tests/test-clients/cpp-inlining/main.cpp:39 (inline)
| /usr/include/c++/6.3.1/bits/random.h:1809 (inline)
| /usr/include/c++/6.3.1/bits/random.h:1818 (inline)
| /usr/include/c++/6.3.1/bits/random.h:185 (inline)
...
~~~~~~~~~~~~~~~~
Signed-off-by: Milian Wolff <milian.wolff@kdab.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Yao Jin <yao.jin@linux.intel.com>
Link: http://lkml.kernel.org/r/20170318214928.9047-1-milian.wolff@kdab.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
The 'grep -v "filename"' applied to the objdump command output cause a
side effect eliminating filename:linenr of output of 'objdump -l' if the
object file name and source file name are the same, fix it.
E.g. the output of the following objdump command in symbol__disassemble():
$ objdump -l -d -S -C /home/taeung/hello --start-address=...
/home/taeung/hello: file format elf64-x86-64
Disassembly of section .text:
0000000000400526 <main>:
main():
/home/taeung/hello.c:4
void main()
{
400526: 55 push %rbp
400527: 48 89 e5 mov %rsp,%rbp
/home/taeung/hello.c:5
...
But it uses grep -v "filename" e.g. "/home/taeung/hello" in the objdump
command to remove the first line containing file name and file format
("/home/taeung/hello: file format elf64-x86-64"):
Before:
$ objdump -l -d -S -C /home/taeung/hello | grep /home/taeung/hello
But this causes a side effect, removing filename:linenr too, because the
object file and source file have the same name e.g. "/home/taueng/hello",
"/home/taeung/hello.c"
So more do a better match by using grep -v as below to correctly remove
that first line:
"/home/taeung/hello: file format elf64-x86-64"
After:
$ objdump -l -d -S -C /home/taeung/hello | grep /home/taeung/hello:
Signed-off-by: Taeung Song <treeze.taeung@gmail.com>
Tested-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Wang Nan <wangnan0@huawei.com>
Link: http://lkml.kernel.org/r/1489978617-31396-5-git-send-email-treeze.taeung@gmail.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
If jump target is outside of function range, perf is not handling it
correctly. Especially when target address is lesser than function start
address, target offset will be negative. But, target address declared to
be unsigned, converts negative number into 2's complement. See below
example. Here target of 'jumpq' instruction at 34cf8 is 34ac0 which is
lesser than function start address(34cf0).
34ac0 - 34cf0 = -0x230 = 0xfffffffffffffdd0
Objdump output:
0000000000034cf0 <__sigaction>:
__GI___sigaction():
34cf0: lea -0x20(%rdi),%eax
34cf3: cmp -bashx1,%eax
34cf6: jbe 34d00 <__sigaction+0x10>
34cf8: jmpq 34ac0 <__GI___libc_sigaction>
34cfd: nopl (%rax)
34d00: mov 0x386161(%rip),%rax # 3bae68 <_DYNAMIC+0x2e8>
34d07: movl -bashx16,%fs:(%rax)
34d0e: mov -bashxffffffff,%eax
34d13: retq
perf annotate before applying patch:
__GI___sigaction /usr/lib64/libc-2.22.so
lea -0x20(%rdi),%eax
cmp -bashx1,%eax
v jbe 10
v jmpq fffffffffffffdd0
nop
10: mov _DYNAMIC+0x2e8,%rax
movl -bashx16,%fs:(%rax)
mov -bashxffffffff,%eax
retq
perf annotate after applying patch:
__GI___sigaction /usr/lib64/libc-2.22.so
lea -0x20(%rdi),%eax
cmp -bashx1,%eax
v jbe 10
^ jmpq 34ac0 <__GI___libc_sigaction>
nop
10: mov _DYNAMIC+0x2e8,%rax
movl -bashx16,%fs:(%rax)
mov -bashxffffffff,%eax
retq
Signed-off-by: Ravi Bangoria <ravi.bangoria@linux.vnet.ibm.com>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Chris Riyder <chris.ryder@arm.com>
Cc: Kim Phillips <kim.phillips@arm.com>
Cc: Markus Trippelsdorf <markus@trippelsdorf.de>
Cc: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Naveen N. Rao <naveen.n.rao@linux.vnet.ibm.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Taeung Song <treeze.taeung@gmail.com>
Cc: linuxppc-dev@lists.ozlabs.org
Link: http://lkml.kernel.org/r/1480953407-7605-3-git-send-email-ravi.bangoria@linux.vnet.ibm.com
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Before this patch the '_raw_spin_lock_irqsave' and 'update_rq_clock' operands
were appearing just as hexadecimal numbers:
update_blocked_averages /proc/kcore
│ push %r12
│ push %rbx
│ and $0xfffffffffffffff0,%rsp
│ sub $0x40,%rsp
│ add -0x662cac00(,%rdi,8),%rax
│ mov %rax,%rbx
│ mov %rax,%rdi
│ mov %rax,0x38(%rsp)
│ → callq _raw_spin_lock_irqsave
│ mov %rbx,%rdi
│ mov %rax,0x30(%rsp)
│ → callq update_rq_clock
│ mov 0x8d0(%rbx),%rax
│ lea 0x8d0(%rbx),%r11
To check that all is right one can always use the 'o' hotkey and see
the original objdump -dS output, that for this case is:
update_blocked_averages /proc/kcore
│ffffffff990d5489: push %r12
│ffffffff990d548b: push %rbx
│ffffffff990d548c: and $0xfffffffffffffff0,%rsp
│ffffffff990d5490: sub $0x40,%rsp
│ffffffff990d5494: add -0x662cac00(,%rdi,8),%rax
│ffffffff990d549c: mov %rax,%rbx
│ffffffff990d549f: mov %rax,%rdi
│ffffffff990d54a2: mov %rax,0x38(%rsp)
│ffffffff990d54a7: → callq 0xffffffff997eb7a0
│ffffffff990d54ac: mov %rbx,%rdi
│ffffffff990d54af: mov %rax,0x30(%rsp)
│ffffffff990d54b4: → callq 0xffffffff990c7720
│ffffffff990d54b9: mov 0x8d0(%rbx),%rax
│ffffffff990d54c0: lea 0x8d0(%rbx),%r11
Use the 'h' hotkey to see a list of available hotkeys.
More work needed to cover operands for other instructions, such as 'mov',
that can resolve variable names, etc.
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Chris Riyder <chris.ryder@arm.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Hemant Kumar <hemant@linux.vnet.ibm.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Markus Trippelsdorf <markus@trippelsdorf.de>
Cc: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Michael Ellerman <mpe@ellerman.id.au>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Naveen N. Rao <naveen.n.rao@linux.vnet.ibm.com>
Cc: Pawel Moll <pawel.moll@arm.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Cc: Ravi Bangoria <ravi.bangoria@linux.vnet.ibm.com>
Cc: Russell King <rmk+kernel@arm.linux.org.uk>
Cc: Taeung Song <treeze.taeung@gmail.com>
Cc: Wang Nan <wangnan0@huawei.com>
Link: http://lkml.kernel.org/n/tip-xqgtw9mzmzcjgwkis9kiiv1p@git.kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
I wanted to know the hottest path through a function and figured the
branch-stack (LBR) information should be able to help out with that.
The below uses the branch-stack to create basic blocks and generate
statistics from them.
from to branch_i
* ----> *
|
| block
v
* ----> *
from to branch_i+1
The blocks are broken down into non-overlapping ranges, while tracking
if the start of each range is an entry point and/or the end of a range
is a branch.
Each block iterates all ranges it covers (while splitting where required
to exactly match the block) and increments the 'coverage' count.
For the range including the branch we increment the taken counter, as
well as the pred counter if flags.predicted.
Using these number we can find if an instruction:
- had coverage; given by:
br->coverage / br->sym->max_coverage
This metric ensures each symbol has a 100% spot, which reflects the
observation that each symbol must have a most covered/hottest
block.
- is a branch target: br->is_target && br->start == add
- for targets, how much of a branch's coverages comes from it:
target->entry / branch->coverage
- is a branch: br->is_branch && br->end == addr
- for branches, how often it was taken:
br->taken / br->coverage
after all, all execution that didn't take the branch would have
incremented the coverage and continued onward to a later branch.
- for branches, how often it was predicted:
br->pred / br->taken
The coverage percentage is used to color the address and asm sections;
for low (<1%) coverage we use NORMAL (uncolored), indicating that these
instructions are not 'important'. For high coverage (>75%) we color the
address RED.
For each branch, we add an asm comment after the instruction with
information on how often it was taken and predicted.
Output looks like (sans color, which does loose a lot of the
information :/)
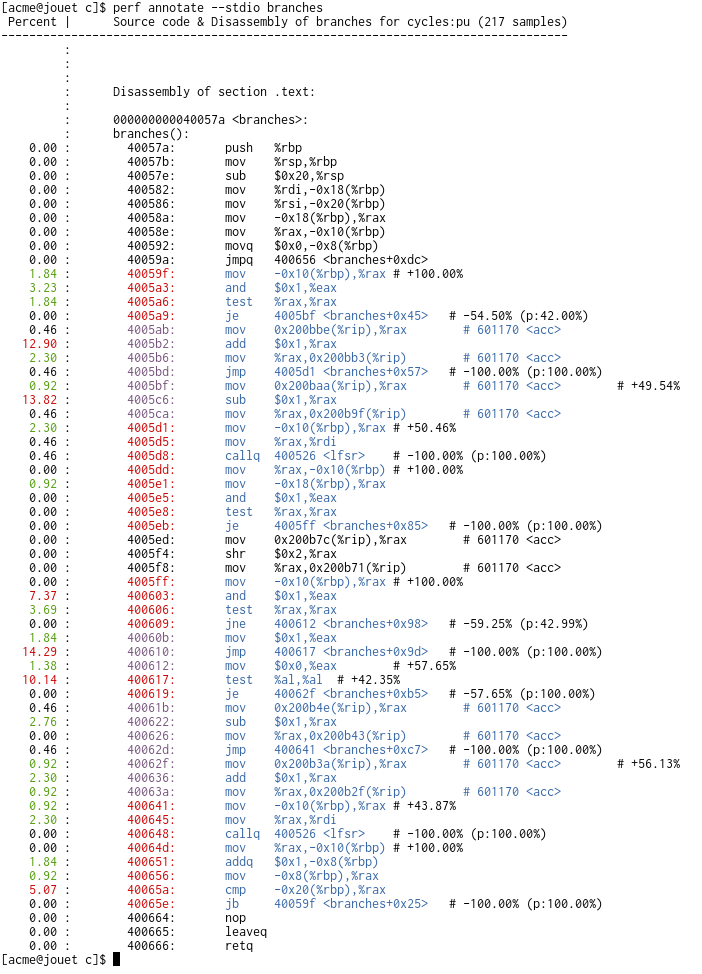
$ perf record --branch-filter u,any -e cycles:p ./branches 27
$ perf annotate branches
Percent | Source code & Disassembly of branches for cycles:pu (217 samples)
---------------------------------------------------------------------------------
: branches():
0.00 : 40057a: push %rbp
0.00 : 40057b: mov %rsp,%rbp
0.00 : 40057e: sub $0x20,%rsp
0.00 : 400582: mov %rdi,-0x18(%rbp)
0.00 : 400586: mov %rsi,-0x20(%rbp)
0.00 : 40058a: mov -0x18(%rbp),%rax
0.00 : 40058e: mov %rax,-0x10(%rbp)
0.00 : 400592: movq $0x0,-0x8(%rbp)
0.00 : 40059a: jmpq 400656 <branches+0xdc>
1.84 : 40059f: mov -0x10(%rbp),%rax # +100.00%
3.23 : 4005a3: and $0x1,%eax
1.84 : 4005a6: test %rax,%rax
0.00 : 4005a9: je 4005bf <branches+0x45> # -54.50% (p:42.00%)
0.46 : 4005ab: mov 0x200bbe(%rip),%rax # 601170 <acc>
12.90 : 4005b2: add $0x1,%rax
2.30 : 4005b6: mov %rax,0x200bb3(%rip) # 601170 <acc>
0.46 : 4005bd: jmp 4005d1 <branches+0x57> # -100.00% (p:100.00%)
0.92 : 4005bf: mov 0x200baa(%rip),%rax # 601170 <acc> # +49.54%
13.82 : 4005c6: sub $0x1,%rax
0.46 : 4005ca: mov %rax,0x200b9f(%rip) # 601170 <acc>
2.30 : 4005d1: mov -0x10(%rbp),%rax # +50.46%
0.46 : 4005d5: mov %rax,%rdi
0.46 : 4005d8: callq 400526 <lfsr> # -100.00% (p:100.00%)
0.00 : 4005dd: mov %rax,-0x10(%rbp) # +100.00%
0.92 : 4005e1: mov -0x18(%rbp),%rax
0.00 : 4005e5: and $0x1,%eax
0.00 : 4005e8: test %rax,%rax
0.00 : 4005eb: je 4005ff <branches+0x85> # -100.00% (p:100.00%)
0.00 : 4005ed: mov 0x200b7c(%rip),%rax # 601170 <acc>
0.00 : 4005f4: shr $0x2,%rax
0.00 : 4005f8: mov %rax,0x200b71(%rip) # 601170 <acc>
0.00 : 4005ff: mov -0x10(%rbp),%rax # +100.00%
7.37 : 400603: and $0x1,%eax
3.69 : 400606: test %rax,%rax
0.00 : 400609: jne 400612 <branches+0x98> # -59.25% (p:42.99%)
1.84 : 40060b: mov $0x1,%eax
14.29 : 400610: jmp 400617 <branches+0x9d> # -100.00% (p:100.00%)
1.38 : 400612: mov $0x0,%eax # +57.65%
10.14 : 400617: test %al,%al # +42.35%
0.00 : 400619: je 40062f <branches+0xb5> # -57.65% (p:100.00%)
0.46 : 40061b: mov 0x200b4e(%rip),%rax # 601170 <acc>
2.76 : 400622: sub $0x1,%rax
0.00 : 400626: mov %rax,0x200b43(%rip) # 601170 <acc>
0.46 : 40062d: jmp 400641 <branches+0xc7> # -100.00% (p:100.00%)
0.92 : 40062f: mov 0x200b3a(%rip),%rax # 601170 <acc> # +56.13%
2.30 : 400636: add $0x1,%rax
0.92 : 40063a: mov %rax,0x200b2f(%rip) # 601170 <acc>
0.92 : 400641: mov -0x10(%rbp),%rax # +43.87%
2.30 : 400645: mov %rax,%rdi
0.00 : 400648: callq 400526 <lfsr> # -100.00% (p:100.00%)
0.00 : 40064d: mov %rax,-0x10(%rbp) # +100.00%
1.84 : 400651: addq $0x1,-0x8(%rbp)
0.92 : 400656: mov -0x8(%rbp),%rax
5.07 : 40065a: cmp -0x20(%rbp),%rax
0.00 : 40065e: jb 40059f <branches+0x25> # -100.00% (p:100.00%)
0.00 : 400664: nop
0.00 : 400665: leaveq
0.00 : 400666: retq
(Note: the --branch-filter u,any was used to avoid spurious target and
branch points due to interrupts/faults, they show up as very small -/+
annotations on 'weird' locations)
Committer note:
Please take a look at:
http://vger.kernel.org/~acme/perf/annotate_basic_blocks.png
To see the colors.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Tested-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Andi Kleen <andi@firstfloor.org>
Cc: Anshuman Khandual <khandual@linux.vnet.ibm.com>
Cc: David Carrillo-Cisneros <davidcc@google.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Kan Liang <kan.liang@intel.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Stephane Eranian <eranian@google.com>
[ Moved sym->max_coverage to 'struct annotate', aka symbol__annotate(sym) ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
If dso__build_id_filename(..., NULL, ...) returns !NULL its because it
allocated it, so, when reaching the 'if (dso__is_kcore()) test, we
already checked that and were just "fallbacking" to using
dso->long_name, but without freeing filename, thus leaking it.
Fix it by adding the dso__is_kcore() test to the 'or' group just after
it, the one containing the full fallback code, including freeing the
filename.
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Wang Nan <wangnan0@huawei.com>
Fixes: ee205503f2 ("perf tools: Fix annotation with kcore")
Link: http://lkml.kernel.org/n/tip-qi4rpjq8yo6myvg99kkgt0xz@git.kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
{kind=link}