I wanted to know the hottest path through a function and figured the
branch-stack (LBR) information should be able to help out with that.
The below uses the branch-stack to create basic blocks and generate
statistics from them.
from to branch_i
* ----> *
|
| block
v
* ----> *
from to branch_i+1
The blocks are broken down into non-overlapping ranges, while tracking
if the start of each range is an entry point and/or the end of a range
is a branch.
Each block iterates all ranges it covers (while splitting where required
to exactly match the block) and increments the 'coverage' count.
For the range including the branch we increment the taken counter, as
well as the pred counter if flags.predicted.
Using these number we can find if an instruction:
- had coverage; given by:
br->coverage / br->sym->max_coverage
This metric ensures each symbol has a 100% spot, which reflects the
observation that each symbol must have a most covered/hottest
block.
- is a branch target: br->is_target && br->start == add
- for targets, how much of a branch's coverages comes from it:
target->entry / branch->coverage
- is a branch: br->is_branch && br->end == addr
- for branches, how often it was taken:
br->taken / br->coverage
after all, all execution that didn't take the branch would have
incremented the coverage and continued onward to a later branch.
- for branches, how often it was predicted:
br->pred / br->taken
The coverage percentage is used to color the address and asm sections;
for low (<1%) coverage we use NORMAL (uncolored), indicating that these
instructions are not 'important'. For high coverage (>75%) we color the
address RED.
For each branch, we add an asm comment after the instruction with
information on how often it was taken and predicted.
Output looks like (sans color, which does loose a lot of the
information :/)
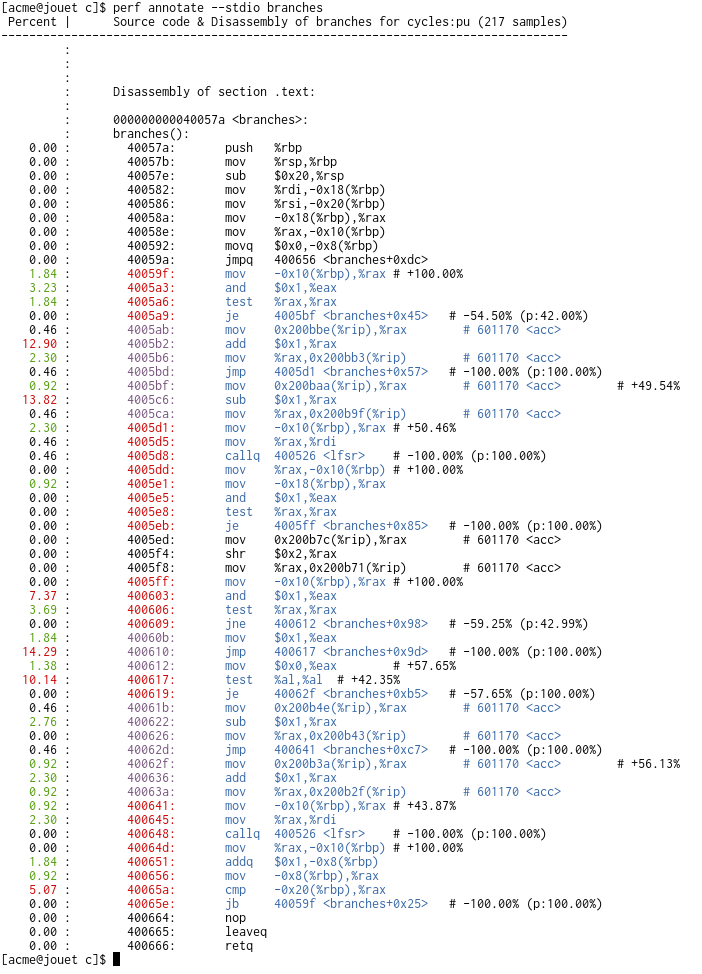
$ perf record --branch-filter u,any -e cycles:p ./branches 27
$ perf annotate branches
Percent | Source code & Disassembly of branches for cycles:pu (217 samples)
---------------------------------------------------------------------------------
: branches():
0.00 : 40057a: push %rbp
0.00 : 40057b: mov %rsp,%rbp
0.00 : 40057e: sub $0x20,%rsp
0.00 : 400582: mov %rdi,-0x18(%rbp)
0.00 : 400586: mov %rsi,-0x20(%rbp)
0.00 : 40058a: mov -0x18(%rbp),%rax
0.00 : 40058e: mov %rax,-0x10(%rbp)
0.00 : 400592: movq $0x0,-0x8(%rbp)
0.00 : 40059a: jmpq 400656 <branches+0xdc>
1.84 : 40059f: mov -0x10(%rbp),%rax # +100.00%
3.23 : 4005a3: and $0x1,%eax
1.84 : 4005a6: test %rax,%rax
0.00 : 4005a9: je 4005bf <branches+0x45> # -54.50% (p:42.00%)
0.46 : 4005ab: mov 0x200bbe(%rip),%rax # 601170 <acc>
12.90 : 4005b2: add $0x1,%rax
2.30 : 4005b6: mov %rax,0x200bb3(%rip) # 601170 <acc>
0.46 : 4005bd: jmp 4005d1 <branches+0x57> # -100.00% (p:100.00%)
0.92 : 4005bf: mov 0x200baa(%rip),%rax # 601170 <acc> # +49.54%
13.82 : 4005c6: sub $0x1,%rax
0.46 : 4005ca: mov %rax,0x200b9f(%rip) # 601170 <acc>
2.30 : 4005d1: mov -0x10(%rbp),%rax # +50.46%
0.46 : 4005d5: mov %rax,%rdi
0.46 : 4005d8: callq 400526 <lfsr> # -100.00% (p:100.00%)
0.00 : 4005dd: mov %rax,-0x10(%rbp) # +100.00%
0.92 : 4005e1: mov -0x18(%rbp),%rax
0.00 : 4005e5: and $0x1,%eax
0.00 : 4005e8: test %rax,%rax
0.00 : 4005eb: je 4005ff <branches+0x85> # -100.00% (p:100.00%)
0.00 : 4005ed: mov 0x200b7c(%rip),%rax # 601170 <acc>
0.00 : 4005f4: shr $0x2,%rax
0.00 : 4005f8: mov %rax,0x200b71(%rip) # 601170 <acc>
0.00 : 4005ff: mov -0x10(%rbp),%rax # +100.00%
7.37 : 400603: and $0x1,%eax
3.69 : 400606: test %rax,%rax
0.00 : 400609: jne 400612 <branches+0x98> # -59.25% (p:42.99%)
1.84 : 40060b: mov $0x1,%eax
14.29 : 400610: jmp 400617 <branches+0x9d> # -100.00% (p:100.00%)
1.38 : 400612: mov $0x0,%eax # +57.65%
10.14 : 400617: test %al,%al # +42.35%
0.00 : 400619: je 40062f <branches+0xb5> # -57.65% (p:100.00%)
0.46 : 40061b: mov 0x200b4e(%rip),%rax # 601170 <acc>
2.76 : 400622: sub $0x1,%rax
0.00 : 400626: mov %rax,0x200b43(%rip) # 601170 <acc>
0.46 : 40062d: jmp 400641 <branches+0xc7> # -100.00% (p:100.00%)
0.92 : 40062f: mov 0x200b3a(%rip),%rax # 601170 <acc> # +56.13%
2.30 : 400636: add $0x1,%rax
0.92 : 40063a: mov %rax,0x200b2f(%rip) # 601170 <acc>
0.92 : 400641: mov -0x10(%rbp),%rax # +43.87%
2.30 : 400645: mov %rax,%rdi
0.00 : 400648: callq 400526 <lfsr> # -100.00% (p:100.00%)
0.00 : 40064d: mov %rax,-0x10(%rbp) # +100.00%
1.84 : 400651: addq $0x1,-0x8(%rbp)
0.92 : 400656: mov -0x8(%rbp),%rax
5.07 : 40065a: cmp -0x20(%rbp),%rax
0.00 : 40065e: jb 40059f <branches+0x25> # -100.00% (p:100.00%)
0.00 : 400664: nop
0.00 : 400665: leaveq
0.00 : 400666: retq
(Note: the --branch-filter u,any was used to avoid spurious target and
branch points due to interrupts/faults, they show up as very small -/+
annotations on 'weird' locations)
Committer note:
Please take a look at:
http://vger.kernel.org/~acme/perf/annotate_basic_blocks.png
To see the colors.
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Tested-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Cc: Alexander Shishkin <alexander.shishkin@linux.intel.com>
Cc: Andi Kleen <andi@firstfloor.org>
Cc: Anshuman Khandual <khandual@linux.vnet.ibm.com>
Cc: David Carrillo-Cisneros <davidcc@google.com>
Cc: Jiri Olsa <jolsa@kernel.org>
Cc: Kan Liang <kan.liang@intel.com>
Cc: Linus Torvalds <torvalds@linux-foundation.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Stephane Eranian <eranian@google.com>
[ Moved sym->max_coverage to 'struct annotate', aka symbol__annotate(sym) ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
The 'annotate' tool does some filtering in the entries in a DSO but
forgot to reset the cache done in dso__find_symbol(), cauxing a SEGV:
[root@zoo ~]# perf annotate netlink_poll
perf: Segmentation fault
-------- backtrace --------
perf[0x526ceb]
/lib64/libc.so.6(+0x34960)[0x7faedfbe0960]
perf(rb_erase+0x223)[0x499d63]
perf[0x4213e9]
perf[0x4bc123]
perf[0x4bc621]
perf[0x4bf26b]
perf[0x4bc855]
perf(perf_session__process_events+0x340)[0x4bddc0]
perf(cmd_annotate+0x6bb)[0x421b5b]
perf[0x479063]
perf(main+0x60a)[0x42098a]
/lib64/libc.so.6(__libc_start_main+0xf0)[0x7faedfbcbfe0]
perf[0x420aa9]
[0x0]
[root@zoo ~]#
Fix it by reseting the find cache when removing symbols.
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: Borislav Petkov <bp@suse.de>
Cc: David Ahern <dsahern@gmail.com>
Cc: Frederic Weisbecker <fweisbec@gmail.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Stephane Eranian <eranian@google.com>
Fixes: b685ac22b4 ("perf symbols: Add front end cache for DSO symbol lookup")
Link: http://lkml.kernel.org/n/tip-b2y9x46y0t8yem1ive41zqyp@git.kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
This adds the basic infrastructure to keep track of cycle counts per
basic block for annotate. We allocate an array similar to the normal
accounting, and then account branch cycles there.
We handle two cases:
cycles per basic block with start and cycles per branch (these are later
used for either IPC or just cycles per BB)
In the start case we cannot handle overlaps, so always the longest basic
block wins.
For the cycles per branch case everything is accurately accounted.
v2: Remove unnecessary checks. Slight restructure. Move
symbol__get_annotation to another patch. Move histogram allocation.
v3: Merged with current tree
Signed-off-by: Andi Kleen <ak@linux.intel.com>
Acked-by: Jiri Olsa <jolsa@kernel.org>
Cc: Namhyung Kim <namhyung@kernel.org>
Link: http://lkml.kernel.org/r/1437233094-12844-4-git-send-email-andi@firstfloor.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
In addition to using refcounts for the struct thread lifetime
management, we need to protect access to machine->threads from
concurrent access.
That happens in 'perf top', where a thread processes events, inserting
and deleting entries from that rb_tree while another thread decays
hist_entries, that end up dropping references and ultimately deleting
threads from the rb_tree and releasing its resources when no further
hist_entry (or other data structures, like in 'perf sched') references
it.
So the rule is the same for refcounts + protected trees in the kernel,
get the tree lock, find object, bump the refcount, drop the tree lock,
return, use object, drop the refcount if no more use of it is needed,
keep it if storing it in some other data structure, drop when releasing
that data structure.
I.e. pair "t = machine__find(new)_thread()" with a "thread__put(t)", and
"perf_event__preprocess_sample(&al)" with "addr_location__put(&al)".
The addr_location__put() one is because as we return references to
several data structures, we may end up adding more reference counting
for the other data structures and then we'll drop it at
addr_location__put() time.
Acked-by: David Ahern <dsahern@gmail.com>
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: Borislav Petkov <bp@suse.de>
Cc: Don Zickus <dzickus@redhat.com>
Cc: Frederic Weisbecker <fweisbec@gmail.com>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Namhyung Kim <namhyung@kernel.org>
Cc: Stephane Eranian <eranian@google.com>
Link: http://lkml.kernel.org/n/tip-bs9rt4n0jw3hi9f3zxyy3xln@git.kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Currently vmlinux_path__init() only tries to find vmlinux file from
current directory, /boot and some canonical directories with version
number of the running kernel. This can be a problem when reporting old
data recorded on a kernel version not running currently.
We can use --symfs option for this but it's annoying for user to do it
always. As we already have the info in the perf.data file, it can be
changed to use it for the search automatically.
Before:
$ perf report
...
# Samples: 4K of event 'cpu-clock'
# Event count (approx.): 1067250000
#
# Overhead Command Shared Object Symbol
# ........ .......... ................. ..............................
71.87% swapper [kernel.kallsyms] [k] recover_probed_instruction
After:
# Overhead Command Shared Object Symbol
# ........ .......... ................. ....................
71.87% swapper [kernel.kallsyms] [k] native_safe_halt
This requires to change signature of symbol__init() to receive struct
perf_session_env *.
Reported-by: Minchan Kim <minchan@kernel.org>
Signed-off-by: Namhyung Kim <namhyung@kernel.org>
Cc: Adrian Hunter <adrian.hunter@intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Ingo Molnar <mingo@kernel.org>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Masami Hiramatsu <masami.hiramatsu.pt@hitachi.com>
Cc: Minchan Kim <minchan@kernel.org>
Cc: Namhyung Kim <namhyung.kim@lge.com>
Cc: Paul Mackerras <paulus@samba.org>
Cc: Peter Zijlstra <a.p.zijlstra@chello.nl>
Cc: Stephane Eranian <eranian@google.com>
Link: http://lkml.kernel.org/r/1407825645-24586-14-git-send-email-namhyung@kernel.org
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
Currently, accounting each sample is done in multiple places - once
when adding them to the input tree, other when adding them to the
output tree. It's not only confusing but also can cause a subtle
problem since concurrent processing like in perf top might see the
updated stats before adding entries into the output tree - like seeing
more (blank) lines at the end and/or slight inaccurate percentage.
To fix this, only account the entries when it's moved into the output
tree so that they cannot be seen prematurely. There're some
exceptional cases here and there - they should be addressed separately
with comments.
Signed-off-by: Namhyung Kim <namhyung@kernel.org>
Link: http://lkml.kernel.org/r/1398327843-31845-7-git-send-email-namhyung@kernel.org
Signed-off-by: Jiri Olsa <jolsa@kernel.org>
This patch adds support for the new PERF_RECORD_MMAP2 record type
exposed by the kernel. This is an extended PERF_RECORD_MMAP record.
It adds for each file-backed mapping the device major, minor number and
the inode number and generation.
This triplet uniquely identifies the source of a file-backed mapping. It
can be used to detect identical virtual mappings between processes, for
instance.
The patch will prefer MMAP2 over MMAP.
Signed-off-by: Stephane Eranian <eranian@google.com>
Cc: Andi Kleen <ak@linux.intel.com>
Cc: David Ahern <dsahern@gmail.com>
Cc: Ingo Molnar <mingo@elte.hu>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Namhyung Kim <namhyung.kim@lge.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Link: http://lkml.kernel.org/r/1377079825-19057-3-git-send-email-eranian@google.com
[ Cope with 314add6 "Change machine__findnew_thread() to set thread pid",
fix 'perf test' regression test entry affected,
use perf_missing_features.mmap2 to fallback to not using .mmap2 in older kernels,
so that new tools can work with kernels where this feature is not present ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
perf record has a new option -W that enables weightened sampling.
Add sorting support in top/report for the average weight per sample and the
total weight sum. This allows to both compare relative cost per event
and the total cost over the measurement period.
Add the necessary glue to perf report, record and the library.
v2: Merge with new hist refactoring.
v3: Fix manpage. Remove value check.
Rename global_weight to weight and weight to local_weight.
v4: Readd sort keys to manpage
v5: Move weight to end
v6: Move weight to template
v7: Rename weight key.
Original patch from Andi modified by Stephane Eranian <eranian@google.com>
to include ONLY the weight supporting code and apply to pristine 3.8.0-rc4.
Signed-off-by: Andi Kleen <ak@linux.intel.com>
Cc: Ingo Molnar <mingo@elte.hu>
Cc: Jiri Olsa <jolsa@redhat.com>
Cc: Namhyung Kim <namhyung.kim@lge.com>
Cc: Peter Zijlstra <peterz@infradead.org>
Link: http://lkml.kernel.org/r/1359040242-8269-6-git-send-email-eranian@google.com
[ committer note: changed to cope with fc5871ed and the hists_link perf test entry ]
Signed-off-by: Arnaldo Carvalho de Melo <acme@redhat.com>
{kind=link}